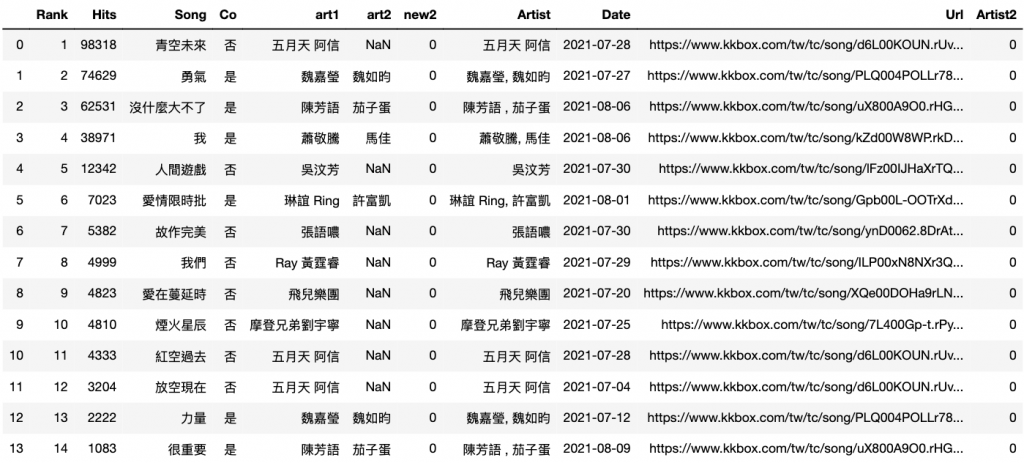
點我下載:song_rank3.csv
import pandas as pd
with open("data/song_rank3.csv") as f:
p = pd.read_csv(f)
p
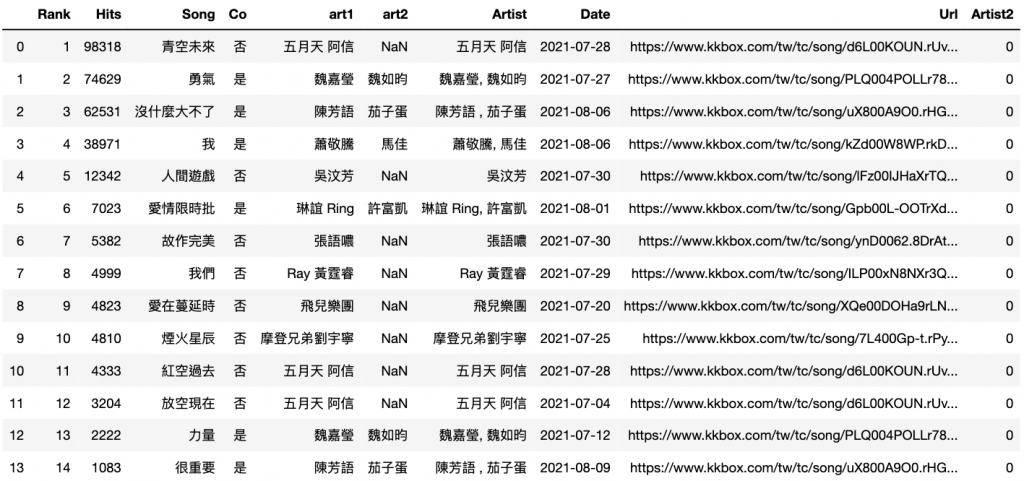
p.columns
Index(['Rank', 'Hits', 'Song', 'Co', 'art1', 'art2', 'Artist', 'Date', 'Url',
'Artist2'],
dtype='object')
p.columns.get_loc("Artist")
6
p.insert(6, 'new', 0, allow_duplicates=True)
p.insert(6+1, 'new2', 0, allow_duplicates=True)
p
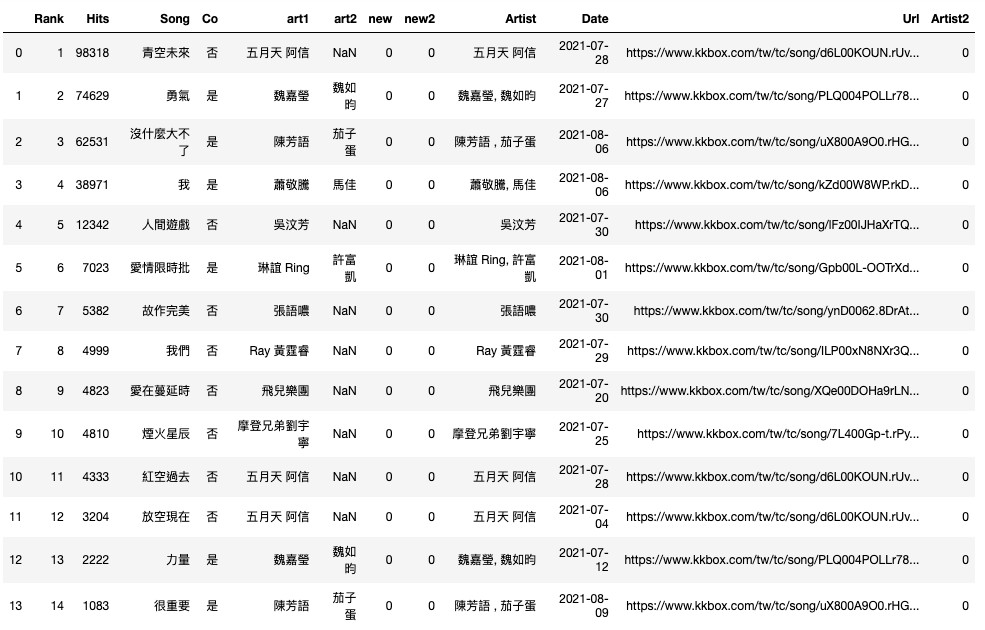
p.columns
Index(['Rank', 'Hits', 'Song', 'Co', 'art1', 'art2', 'new', 'new2', 'Artist',
'Date', 'Url', 'Artist2'],
dtype='object')
p.columns.get_loc('new') # python 是 完全比對'new' 與R不同 R是部分比對 "new"所以"new2"也會是
6
# 要用index版的location
# 如果是 一般版location df.loc[:,'col':'col2']
p.iloc[:,6:6+1]

p.iloc[:,6:6+1].columns
Index(['new'], dtype='object')
colname= p.iloc[:,6:6+1].columns
p.drop(columns = colname)